P1. 기존 데이터 이식
P2. 데이터베이스 언어 (Cypher)
P3. Graph Apps - Neo4j Bloom (가시화), NeoDash (Feature 트래킹)
P4. graph data science - 알고리즘 (ex: pagerank, community detection)
P5. Gephi와 연동, Large network 가시화
P6. Python 프로그램과 연동, 주기적 DB 업데이트
*굵게 표시한 목표는 이 글에서 다루는 내용
이번 글에서는 Neo4j 내부 GraphApps들과 알고리즘을 다뤄보겠다.
Graph Apps 설치법
Graph Apps는 Neo4j Desktop 왼쪽 상단 아이콘 중 제일 아래를 누르면 확인해볼 수 있다. 기본으로 몇가지 앱이 있고, 원하는 App은 Graph Apps Gallery에 들어가서 추가할 수 있다.
이 때, Gallery에서 Install 버튼을 눌러도 반응이 없는 경우가 있다. 친절하게?! 같은 페이지 제일 밑에서 대응방법을 가르쳐 주고 있다.

나는 저 설명대로도 설치가 되지 않았다. 내 경우 해결방법은 다음과 같았다.
원하는 앱의 저 아이콘 모양을 클릭해보면, 웹 브라우저에 이상한 창이 뜰 것이다.

여기서 주소를 복사한 뒤에, Neo4j Desktop으로 돌아와서

여기다가 붙여넣고, Install을 누르면 설치가 된다.
Bloom
처음 살펴볼 앱은 Bloom이다. 가시화를 위한 앱인데, 엄청 큰 Graph의 가시화는 지원하지 않는다. (Gephi의 필요성)
사용 전에 먼저, 관찰할 Data의 카테고리를 지정할 필요가 있다. 왼쪽 위 컨트롤 창을 열어서 'Add category'에서 가시화를 원하는 node를 추가해주면 된다.
이후, 사용법은 직관적이다. Search 란에 가시화를 원하는 node를 적으면 된다. 단 이 창은 Cyper를 지원하지 않으므로,
Media Article
처럼 그냥 적는다.
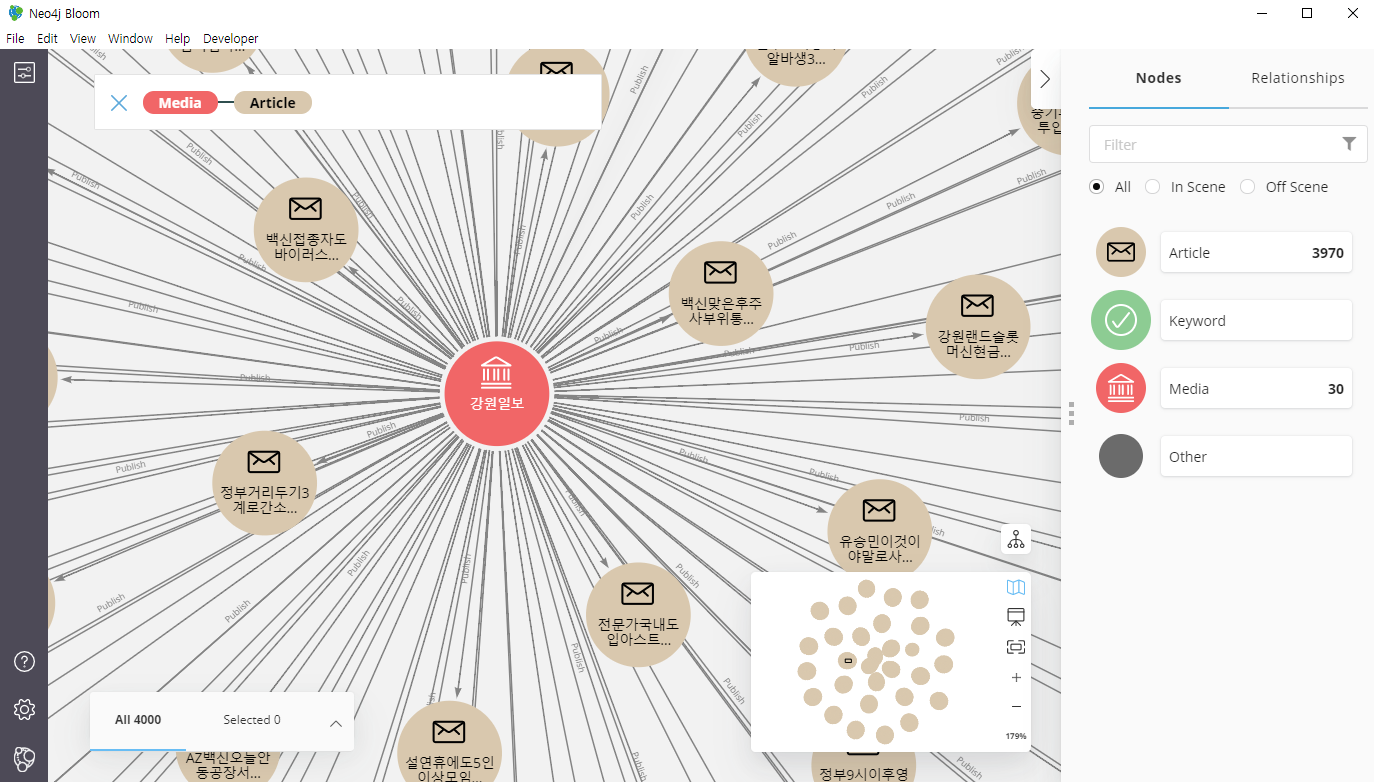
원하는 node의 색상과 아이콘은 오른쪽 화면의 그림을 클릭해보면 정할 수 있다. node가 지닌 property에 따라서 사이즈를 다르게 설정하거나 하는 것도 가능하다.
Bloom은 아주 큰 node들의 전체 모습을 보기에는 적절치 않다. 작은 network에서 직관적인 관계를 보기에 적합해 보인다.
혹은, 다음과 같은 사용도 가능하다.
왼쪽 위 컨트롤 창을 눌러보면, 'Search phrases'라는 탭이 있는데, 여기서 'Add Search phrase'를 누르면, Cypher 언어를 이용한 매크로를 작성할 수 있다.
예를 들어, 이전 Browser에서 확인해 보았던 두 Keyword를 함께 인용하고 있는 Article을 가시화 해보자.
(:Keyword)<-[:Include]-(:Article)-[:Include]->(:Keyword)

'Search phrase' : 이건 내가 검색 창에서 입력할 message에 해당한다. ${값} 부분은 인자를 받아서 Cypher 언어로 전달해주는 부분이다.
'Description' : phrase를 설명하는 부분이다.
'Cypher query': Cypher 언어로 가시화 할 data를 return하는 곳이다. 여기서는 인자로 받은 $k1과 $k2 사이의 'Article'로 이뤄진 path를 Return 하고 있다.
Search phrase에서 인자를 받으면 밑에 parameter를 설정하는 부분이 나온다. 이 때, parameter가 label의 property라면, 추천이나 자동완성 기능을 지원해준다. 나는 Keyword의 name을 인자로 받기 때문에 위와 같이 설정.
이제 만든 phrase를 이용해보자.
'백신'과 '논란'이라는 keyword를 포함한 article을 찾아보자.

3개의 기사가 검색된다. 적절히 잘 검색된 것을 볼 수 있다. 자주 쓰는 검색 기능을 phrase로 두고, 관계를 검색한다면 굉장히 유용할 것 같다.
NeoDash
NeoDash는 자주 쓰는 feature들을 가시화 하여, Data가 업데이트 될 때마다 변화를 트랙킹 하기에 좋아 보인다.
지원하는 가시화 형식은 Table, Graph, Line Chart, Bar Chart, Raw JSON, Selection, Markdown이 있다.
아주 심플하고 명료하게 가시화 해주는 대신, 가시화에 있어서 자유도는 높지 않다. 유용한 Feature들을 property로 정해두고, 가시화 하는 방식으로 이용하면 유용할 것 같다.

Plugin 활용법 (함수, 알고리즘)
다음은 아주 중요한 Plugin 활용법.
다음 화면에서 DBMS를 클릭하면 우측에 Plugin들을 설치할 수 있는 화면이 나온다. APOC과 Graph Data Science Library 둘 다 아주 유용하므로, 설치를 한다. (서버를 재시작할 필요가 있음)

먼저, Apoc 함수는 Awesome Procedures On Cypher 의 줄인말이다. 유용한 함수들이 총집합한 라이브러리다.
가장 먼저 Apoc이 필요한 계기는 아주 큰 Relationship을 만들 때 생기는 memory 문제를 해결하기 위해서 였다.
현재 생성된 network의 구조는 다음과 같다.
(:Media)-[:Publish]->(:Article)-[:Include]->(:Keyword)이 자료 구조는 3 종류의 node 간에 관계를 갖는 구조이기 때문에, 네트워크 과학에서 보통 활용하는 Community 추출이나, 중요도 선정을 위해서는 한 종류의 node로 이루어진 network를 구축할 필요가 있었다.
한가지 가능한 접근법으로 Article들이 공통 Keyword를 인용할 경우. Article간에 Link를 연결하는 방법을 생각해 볼 수 있다.
이를 위해 쓴 명령어는 다음과 같다.
MATCH (a:Article)-[:Include]->(:Keyword)<-[:Include]-(b:Article)
WHERE id(a) > id(b)
WITH a, b, count(*) as weight
MERGE (a)-[r:Inter]-(b)
ON CREATE SET r.w = weight
Article a로부터 b로 keyword를 통해 연결되는 path를 검색하고, 그 개수를 weight로 지니는 링크 Inter를 생성하라는 명령어다. 여기서 id는 node가 생성될 때 자동으로 생성되는 고유 수치인데, 반대편 방향의 중복을 줄이기 위해 사용했다.
이걸 실행해보면 OutOfMemoryError가 발생하며, DBMS memory heap의 최대크기를 올려보라고 조언을 해준다. 그런데, 이걸 Apoc의 iterate함수를 이용해서 해결할 수 있다.
apoc.periodic.iterate
이 함수를 이용한 명령어는 다음과 같다.
CALL apoc.periodic.iterate(
'MATCH (a:Article)-[:Include]->(:Keyword)<-[:Include]-(b:Article) WHERE id(a) > id(b)
RETURN a, b, count(*) as weight',
'MERGE (a)-[r:Inter]-(b)
ON CREATE SET r.w = weight',
{batchSize : 10000})
YIELD batch, operations함수에 들어가는 첫번째 문장은 "a data-driven statement (어떤 data를 다룰 것인가)" 에 해당한다. 우리가 다룰 data를 return으로 반환해주면 된다.
두번째 문장은 "an operation statement (무엇을 할 것인가)" 에 해당한다. a와 b를 Inter라는 relationship으로 묶어주면 된다.
batchSize는 한번에 처리할 개수에 해당한다. 이 동작을 몇 번에 나눠서 함으로써 메모리 문제를 해결하는 것이다.
실행 결과는 다음과 같다.

총 91 번의 commit이 이루어졌는데, 10000개의 batchSize로 91번 수행하여, 전체 903077번 (추가된 link의 개수)의 operation을 수행한 것을 알 수 있다.

이제 단일 node계층의 network를 만들었으니, 그래프 데이터 사이언스 라이브러리를 이용해서 알고리즘을 몇 개 돌려보자.
GDS - PageRank
GDS(Graph Data Science library)에는 Node의 중요도를 평가하는데 유용한 pagerank 알고리즘이 내장되어 있다.
사용법은 다음과 같다.
1. 분석할 graph 특정
2. 분석
1. graph만들기
CALL gds.graph.create('Article_Inter', 'Article', 'Inter', {relationshipProperties: 'w'})처음 인자는 그래프 이름. 두번째 인자는 node, 세번째 인자는 relationship의 label을 넣어준다. relationship 속성으로는 Inter의 weight property인 'w'를 넣어준다.
2. 분석
CALL gds.pageRank.write('Article_Inter',
{maxIterations: 20, dampingFactor: 0.85, relationshipWeightProperty: 'w', writeProperty: 'pagerank'})
YIELD nodePropertiesWritten, ranIterations아까 만든 'Article_Inter' 그래프를 불러와서 그 안에서 pagerank를 계산하고, 계산된 값을 node의 'pagerank'라는 property에 set해주는 함수다.


Write함수 외에도, 계산 결과만을 반환하는 함수 (stream), summary를 보여주는 함수 (Stats) 들도 있으니 원하는 방식으로 이용이 가능하다.
GDS - community detection (louvain)
다음으로는 community detection을 해보자.
아까 만들어 둔 graph는 그대로 이용하고, louvain 함수를 이용 해서 node property에 community를 set 해보자.
CALL gds.louvain.write('Article_Inter',
{relationshipWeightProperty: 'w', writeProperty: 'community' })
YIELD communityCount, modularity, modularities(여기서 'w'는 relationship의 weight인 'w'를 이용하기 위해 입력하는 인자다)
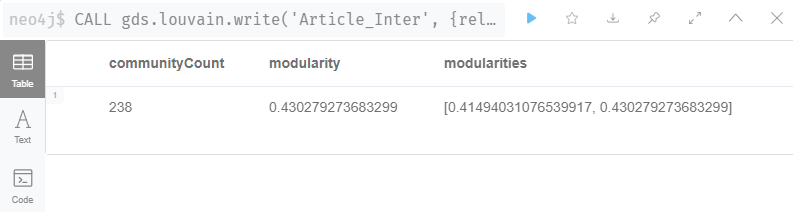
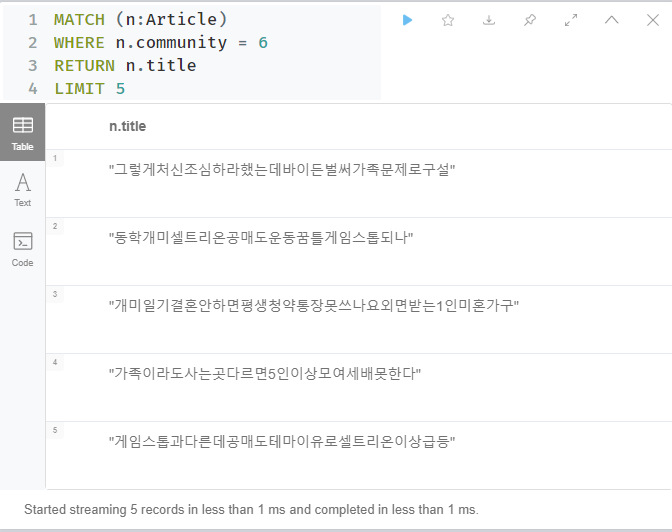
이 외에도 정말 많은 알고리즘들이 있다.

Neo4j의 GDS가 정말!! 좋은 이유는 document가 network science를 공부하기에 정말 유용하다는 점이다. (가벼운 교과서 수준) 사실 Neo4j도 network 과학의 algorithm들을 공부하면서 우연히 알게 되었다.
그냥 공부를 위한 목적으로라도 GDS document 사이트를 방문하는 것을 추천!
neo4j.com/docs/graph-data-science/current/algorithms/
Algorithms - Neo4j Graph Data Science
This chapter describes each of the algorithms in the Neo4j Graph Data Science library, including algorithm tiers, execution modes and general syntax.
neo4j.com
'공부 > 가짜 뉴스' 카테고리의 다른 글
| [메타 언론 플랫폼] 전반적인 계획 (+ Github pages 호스팅 예제) (0) | 2021.03.24 |
|---|---|
| [Neo4j] Gephi와 연동, large network 가시화 (0) | 2021.03.05 |
| [Neo4j] 그래프를 다루는 데이터베이스 - 도입 (2) | 2021.03.05 |
| [뉴스 가시화] 네이버 랭킹 뉴스 키워드 네트워크 가시화 - 2월 (0) | 2021.03.01 |
| [연습] 네이버 랭킹 뉴스 가시화 with Python & Gephi (6) | 2021.01.16 |



댓글